

ШІ-моделі скоріше збрешуть, ніж зізнаються в незнанні чого-небудь. Така поведінка стає дедалі очевиднішою в міру зростання мовної моделі, йдеться в дослідженні, опублікованому в Nature.
Штучний інтелект схильний відповідати з упевненістю, навіть якщо відповідь фактично невірна, тому що його навчили вірити в цю інформацію. Моделі не усвідомлюють власного невігластва, зазначили автори.
Більші моделі зазвичай демонструють поліпшену продуктивність під час виконання складних завдань, але це не гарантує постійну точність, особливо під час виконання простих завдань.
Вони помітно рідше уникають складних запитань, намагаючись їх розв’язувати й іноді даючи неправильні відповіді. На наведеному нижче графіку видно, як моделі видають неправильні результати (червоний колір) замість того, щоб ухилитися від вирішення завдання (світло-блакитний колір).
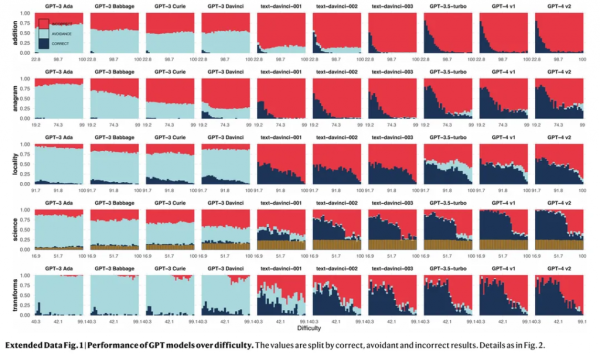
Правильні відповіді відображені темно-синім кольором. Джерело: Nature.
Дослідники зазначили, що цей феномен не пов’язаний зі здатністю великих мовних моделей справлятися з простими завданнями. Просто їх тренують краще розв’язувати складні проблеми. Нейромережі, навчені на величезних, складних масивах даних, більш схильні упускати фундаментальні навички.
Проблема посилюється впевненістю ШІ. Користувачам часто складно визначити, коли він надає точну інформацію, а коли дезінформацію.
Експерти також виявили, що під час поліпшення продуктивності моделі в одній області вона може погіршуватися в іншій.
«Відсоток відповідей, що уникають, рідко зростає швидше, ніж відсоток неправильних. Висновок очевидний: помилки, як і раніше, трапляються частіше. Це являє собою інволюцію надійності», — пишуть вони.
Дослідники підкреслили мінуси сучасних методів навчання штучного інтелекту. Налаштування з підкріпленням і людським зворотним зв’язком посилює проблему, оскільки модель не намагається уникнути завдання, з яким вона не впорається.
Нагадаємо, у вересні OpenAI представила нову велику мовну модель o1, навчену методом із підкріпленням для виконання складних міркувань.






